Yesterday afternoon, I had a bit of time on my hands, and a report that someone desperately needed redone. The original author was a support engineer who was trying to learn Ruby and didn’t realize that Ruby hash-maps are case sensitive. In the interest of time, I corrected the issue by downcasing all the keys, and reran the script (which ran successfully, but inelegantly), but I looked at the problem, and once again, found a perfectly lovely use case for the language I love so much, F#.
First off, some of the basics.
open System
// these may not be strictly necessary, but they do help describe
// precisely what data I'm dealing with
module UpperCaseString =
type UpperCaseString = UpperCaseString of string
let private upper (a:string) =
a.ToUpper()
let create (a:string) =
if String.IsNullOrEmpty(a) then None
else Some (UpperCaseString (upper a))
let value (UpperCaseString s) =
s
open UpperCaseString
module FloatingDecimalBetweenZeroAndOne =
type FloatingDecimalBetweenZeroAndOne = FloatingDecimalBetweenZeroAndOne of decimal
let create (a:decimal) =
if a > Decimal.One || a < Decimal.Zero then None else Some (FloatingDecimalBetweenZeroAndOne a) let value (FloatingDecimalBetweenZeroAndOne f) = f let make a = (create a |> Option.get)
open FloatingDecimalBetweenZeroAndOne
Generally, I’ll do this for most business application coding nowadays. Creating a simple type that encapsulates correctness from the get-go (including basic validation) makes it so I don’t have to try to figure out weird results. I know the sorts of things I’m dealing with, and I deal with them from the beginning. Also, given the fundamental problem of the original script I had (the case sensitive hash-maps), ensuring I had a type that enforced upper-casing seemed worthwhile.
Next, the domain.
type Model = Model of UpperCaseString
with static member Value (Model (UpperCaseString s)) = s
type Ticker = Ticker of UpperCaseString
with static member Value (Ticker (UpperCaseString s)) = s
type Holding = { Ticker : Ticker; Allocation : FloatingDecimalBetweenZeroAndOne }
type ModelAllocations = { Model : Model; Holdings : Holding list }
type ModelWeight = { Model : Model; Weight : FloatingDecimalBetweenZeroAndOne }
type SleevedHolding = { Ticker : Ticker; Model : Model; Allocation : FloatingDecimalBetweenZeroAndOne }
with override x.ToString () = sprintf "%s,%s,%5M" (Ticker.Value x.Ticker) (Model.Value x.Model) (FloatingDecimalBetweenZeroAndOne.value x.Allocation)
// This is the simplest description of what we're doing.
// taking a list of holdings, a list of models and their holdings
// a list of weights to apply to the model, and returning a set of 'sleeved' holdings.
type SleeveProcess = Holding list -> ModelAllocations list -> ModelWeight list -> SleevedHolding list
The problem the original script was attempting to solve was to assign an appropriate ‘Model’ to a holding. A Model is, for sake of brevity, simply an identity (representing the “name” of a standard financial benchmark (like the S&P 500), and a Ticker an identity representing a stock ticker.
A Holding represents an individual stock in a of a portfolio, with the Allocation representing the percentage of the portfolio. ModelAllocations represent a model, and the list of holdings it has (what stocks are in the S&P 500, etc.) ModelWeight represents the approximate weight a portfolio is associated to a given model or benchmark.
E.G. S&P 500 -> 50% , and Russell 3000 -> 50%.
let makeModel str =
UpperCaseString.create str |> Option.get |> Model
let makeTicker str =
UpperCaseString.create str |> Option.get |> Ticker
let holding str all =
{ Ticker = makeTicker str; Allocation = make all }
let makeSleeve t m a = { Ticker = t; Model = m; Allocation = a }
let modelWeight str a = { Model = makeModel str; Weight = make a }
let modelAllocation str h = { Model = makeModel str; Holdings = h }
One of the problems of heavy use of custom types is that you’ll typically want ‘shorthand’ functions for creating the types as necessary. It can be a pain, but difficult to explain results after the fact is worse.
Finally, the meat of it.
let sleeveHoldings holdings models weights =
let findHolding t =
models |>
List.collect (fun n -> n.Holdings
|> List.filter (fun n -> n.Ticker = t)
|> List.map (fun x -> (n.Model, x.Allocation)))
let sleeve h =
let t = h.Ticker
let m = findHolding t // a list of models that hold the security
match m with
| [] ->
weights |>
List.map (fun w ->
let weightTimesAllocation = (value w.Weight * value h.Allocation)
makeSleeve t w.Model (make weightTimesAllocation))
| [(x,_)] -> [makeSleeve t x h.Allocation]
| xs ->
let weightsMap = weights |> List.map (fun n -> (n.Model, value n.Weight)) |> Map.ofList
let total = xs |> List.sumBy (fun (m, w) -> weightsMap.[m] * value (w))
xs |> List.map (fun (m, w) ->
let weightTimesAllocationOverTotal = (value w * weightsMap.[m]) / total
makeSleeve t m (make (weightTimesAllocationOverTotal * value h.Allocation)))
holdings |> List.collect sleeve
First, we define a function to find the models with a given holding, and return that model and the allocation. Then we define a function to sleeve an individual holding. Finally, we call that function over the list of holdings passed in.
A simple set of tests:
let testHoldings = [
holding "A" 0.20m;
holding "B" 0.20m;
holding "C" 0.20m;
holding "D" 0.20m;
holding "E" 0.20m; ]
let testWeights = [
modelWeight "MODEL1" 0.5m;
modelWeight "MODEL2" 0.3m;
modelWeight "MODEL3" 0.2m;
]
let testModelAllocations = [
modelAllocation "MODEL1" [
holding "A" 1.0m;
];
modelAllocation "MODEL2" [
holding "A" 0.5m;
holding "B" 0.3m;
holding "D" 0.2m;
];
modelAllocation "MODEL3" [
holding "B" 0.5m;
holding "C" 0.3m;
holding "D" 0.2m;
]
]
sleeveHoldings testHoldings testModelAllocations testWeights |> List.map (fun m -> m.ToString ())
val it : string list =
["A,MODEL1,0.1538461538461538461538461538";
"A,MODEL2,0.0461538461538461538461538462";
"B,MODEL2,0.0947368421052631578947368421";
"B,MODEL3,0.1052631578947368421052631579"; "C,MODEL3, 0.20";
"D,MODEL2,0.120"; "D,MODEL3,0.080"; "E,MODEL1,0.100"; "E,MODEL2,0.060";
"E,MODEL3,0.040"]
At the financial services firm I work for, this concept of attributing holdings is called ‘sleeving.’


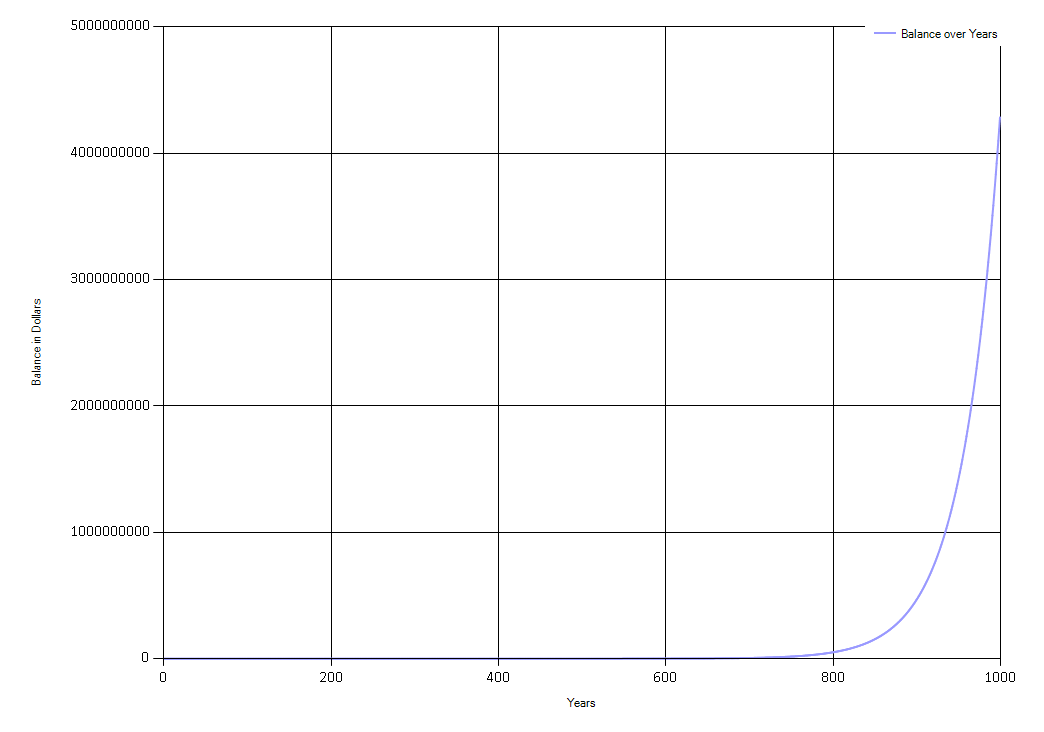
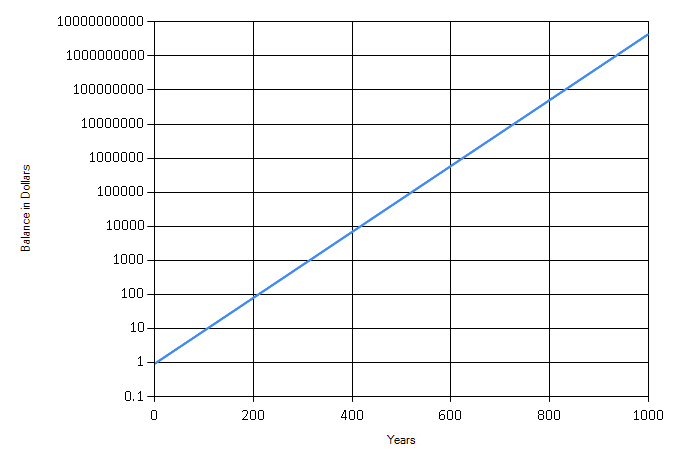 It looks like Fry’s bank account doesn’t get interesting until about 300 years or so. Still, compound interest is a wonder, despite
It looks like Fry’s bank account doesn’t get interesting until about 300 years or so. Still, compound interest is a wonder, despite 